8. RAG를 위한 LangChain의 핵심 구성 요소 및 실습[Retrievers]
1. RAG의 핵심, 문서 검색기 Retriever
1.1. Retriever의 기본형, 벡터DB 기반 Retriever
from langchain.document_loaders import PyPDFLoader
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain_openai import OpenAIEmbeddings
from langchain_community.vectorstores import Chroma
os.environ["OPENAI_API_KEY"] = "YOUR_API_KEY"
#헌법 PDF 파일 로드
loader = PyPDFLoader(r"/content/drive/MyDrive/마소캠퍼스/대한민국 헌법.pdf")
pages = loader.load_and_split()
#PDF 파일을 500자 청크로 분할
text_splitter = RecursiveCharacterTextSplitter(chunk_size=500, chunk_overlap=0)
docs = text_splitter.split_documents(pages)
#ChromaDB에 청크들을 벡터 임베딩으로 저장(OpenAI 임베딩 모델 활용)
db = Chroma.from_documents(docs, OpenAIEmbeddings(model = 'text-embedding-3-small'))
#Chroma를 Retriever로 활용
retriever = db.as_retriever()
retriever.invoke("국회의원의 의무")<결과>

국회의원의 의무에 대한 내용들을 잘 갖고 온다.
#유사 청크 1개만 반환
1.2. 유사 청크 개수 반환하기-> search_kwargs: keyword arguments
#유사 청크 10개만 반환
retriever = db.as_retriever(search_kwargs={"k": 10})
retriever.invoke("국회의원의 의무")
k의 값에 따라 유사 문서 개수를 반환한다. k를 무조건 증가한다고 좋은게 아니라 내가 가진 Vector DB안에 문서들이 어떤 특성을 갖고 있는지, 사용자가 질문하는 것들은 어떤게 있는지에 따라 k의 개수를 정한다. 총 10개의 문서가 도출된다.

1.3. 검색 방식 변경 - MMR
MMR은 쿼리에 대한 (1) 각 문서의 유사성 점수와 (2) 이미 선택된 문서들과의 다양성점수를 조합하여, 각 문서의 최종 점수를 계산합니다.
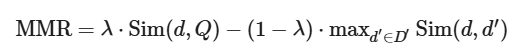
d: 특정문서
d': d와 다른 문서
D: 추출된 문서들의 집합
Q: 사용자의 쿼리
Sim: 시뮬레이터
람다: 가중치
즉, 유사 문서 후보군 중 특정 문서가 후보군 내 문서들 간의 유사성은 낮고, 쿼리와의 유사성이 높은 경우 점수가 높습니다.
(= 사용자 질문과 추출한 문서의 유사성이 높고, 그 문서와 다른 문서들간의 유사성이 낮으면 MMR 점수는 높다. 람다가 높으면 쿼리와 유사도가 높은 문서들이 추출되고, 낮으면 다양한 문서들이 추출된다.)
장점: 기존의 Retriever의 경우, 주어진 쿼리에 대해서 가장 유사한 문서를 뽑아썼다. 유사도 순위 기준으로 k값이 정해지면 그 k개 만큼의 유사 문서를 검색해내는 것이다. 가장 유사한 문서들을 내놨다고 해서 항상 LLM이 좋은 답변을 하는 것은 아니다. 중복되거나 다양하지 않음 문서들이 많은 경우, LLM의 답변이 한곳에 집중되어 사용자 입장에서는 다양한 답변을 받을 수 없다.
2. 실습
2.1.
from langchain.document_loaders import PyPDFLoader
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain_openai import OpenAIEmbeddings
from langchain_community.vectorstores import Chroma
#헌법 PDF 파일 로드
loader = PyPDFLoader(r"/content/drive/MyDrive/마소캠퍼스/대한민국 헌법.pdf")
pages = loader.load_and_split()
#PDF 파일을 500자 청크로 분할
text_splitter = RecursiveCharacterTextSplitter(chunk_size=500, chunk_overlap=0)
docs = text_splitter.split_documents(pages)
#ChromaDB에 청크들을 벡터 임베딩으로 저장(OpenAI 임베딩 모델 활용)
db = Chroma.from_documents(docs, OpenAIEmbeddings(model = 'text-embedding-3-small'))
#Chroma를 Retriever로 활용
retriever = db.as_retriever(
search_type="mmr",
search_kwargs = {"lambda_mult": 0, "fetch_k":10, "k":3}
)
result = retriever.invoke("국회의원의 의무")
for idx, value in enumerate(result):
print(f"{idx+1}번째 유사 문서:")
print(value.page_content[:100])
print("\n\n")
lambad_mult(0~1): 가중치(낮으면 낮을수록 다양성을 중시함)
fetch_k: 10개의 후보 문서
k: fetch_k 개수에서 가장 유사한 문서 추출
<결과>

유사도가 낮고, 다양한 문서들이 추출된다.