6. RAG를 위한 LangChain의 핵심 구성 요소 및 실습[Embeddings]
1. Embeddings의 개념

각각의 차원들이 뜻하는 바는 이 문장의 특성을 나타낸다. 단어의 이중적인 의미를 768차원에 담는다.
즉, 주어진 문장을 몇차원의 벡터 임베딩에 담아내느냐에 따라 문장이 다르다.
2. Embeddings의 원리

대용량의 말뭉치를 통해서 사전학습된 모델을 통해 쉽게 임베딩을 할 수 있다.
이 임베딩 모델은 Transformer 아키텍처에서 인코더 모델을 학습시킨 경우가 많다.
인코더 모델에 굉장히 많은 양의 데이터를 학습을 시키면 이 모델 자체적으로 문장 내에 이런이런 뜻이 있고, 문법적으로 이런이런 순서와 이런이런 뜻을 갖고 있다는 것을 모델이 파악할 수 있게 해준다.
따라서, 사전 학습된 임베딩 모델을 통해 문장을 바로 숫자로 표현 가능하다. (따로 학습이 필요없다.)
임베딩 -> 문장과 문장과의 거리와 유사성을 알 수 있다.
3. Embeddings의 모델의 종류

임베딩은 크게 2가지로 구성된다. 기업에서 제공하는 유료 임베딩 모델과 오픈소스로 제공되는 무료 임베딩이 있다. 유료 임베딩은 사용하는 만큼 비용을 지불하기만 하면 된다.
추가적으로 한국어 자연어 임베딩 처리하는 시스템은 대부분의 유료 임베딩 서비스에서 처리 되어있기 때문에 무료 임베딩을 쓰는 것보다 훨씬 더 정확도가 높게 임베딩이 가능하다.
GPU도 필요 없이 해당 서버에서 임베딩을 하므로 임베딩 자체는 GPU가 필요없다.
4. Embeddings 실습
4.1 OpenAI의 텍스트 임베딩 모델 활용하기
4.1.1. 임베딩 모델 설정하기(여러 문장을 직접 입력)
import os
from langchain_openai import OpenAIEmbeddings
os.environ["OPENAI_API_KEY"] = "Your API KEY"
embeddings_model = OpenAIEmbeddings(model = 'text-embedding-3-small')
embeddings = embeddings_model.embed_documents(
[
"Hi there!",
"Oh, hello!",
"What's your name?",
"My friends call me World",
"Hello World!"
]
)
len(embeddings), len(embeddings[0])
len(embeddings)->5
len( embeddings[0]))-> "Hi there!" -> 1536 차원으로 임베딩 됨.
4.1.2. 문서를 임베딩하기
from langchain_openai import OpenAIEmbeddings
from langchain_community.document_loaders import PyPDFium2Loader
from langchain_text_splitters import RecursiveCharacterTextSplitter
#임베딩 모델 API 호출
embeddings_model = OpenAIEmbeddings(model = 'text-embedding-3-small')
#PDF 문서 로드
loader = PyPDFium2Loader(r"/content/drive/MyDrive/마소캠퍼스/[이슈리포트 2022-2호] 혁신성장 정책금융 동향.pdf")
pages = loader.load()
#PDF 문서를 여러 청크로 분할
text_splitter = RecursiveCharacterTextSplitter(
chunk_size=500,
chunk_overlap=100
)
texts = text_splitter.split_documents(pages)
#OpenAI 임베딩 모델로 청크들을 임베딩 변환하기
embeddings = embeddings_model.embed_documents([i.page_content for i in texts])
len(embeddings), len(embeddings[0])<결과>

4.1.3. [문장 유사도 계산해보기]
1. 임베딩 (내용, 힌트 질문, 힌트 답변)
examples= embeddings_model.embed_documents(
[
"안녕하세요",
"제 이름은 홍두깨입니다.",
"이름이 무엇인가요?",
"랭체인은 유용합니다.",
]
)
#예시 질문과 답변 임베딩
embedded_query_q = embeddings_model.embed_query("이 대화에서 언급된 이름은 무엇입니까?")
embedded_query_a = embeddings_model.embed_query("이 대화에서 언급된 이름은 홍길동입니다.")
2. 문장간의 유사 비교시 사용하는 지표 -> COS_SIM, dot(A,B), norm(A): 길이
from numpy import dot
from numpy.linalg import norm
import numpy as np
def cos_sim(A, B):
return dot(A, B)/(norm(A)*norm(B))
print(cos_sim(embedded_query_q, embedded_query_a))
print(cos_sim(embedded_query_a, examples [1]))
print(cos_sim(embedded_query_a, examples [3]))벡터(문장을 벡터 임베딩)와 벡터간의 유사도를 비교할 시에는 코사인 값을 기준으로 유사도를 찾을 수 있다.
<결과>
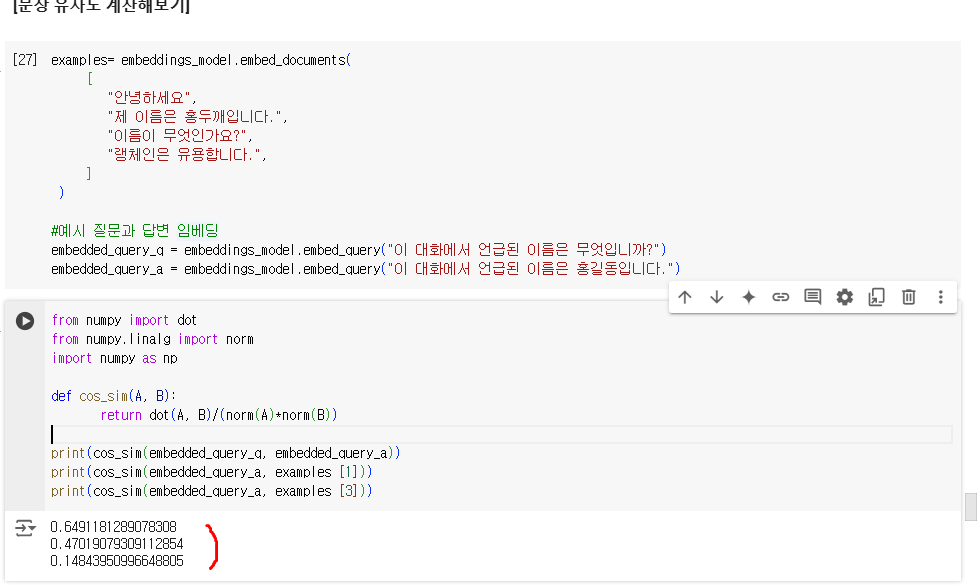
1. 힌트 질문, 힌트 답변의 유사도 -> 0.6491...
2. "제 이름은 홍두께입니다." 와 힌트 대답의 유사도("이름"이라는 단어가 들어가 있음.) ->0.4701...
4.2 HugginFace Embeddings 활용하기 ( 무료 버전)
4.2.1 한글 임베딩 지원 모델
pip install sentence-transformers
from langchain_community.embeddings import HuggingFaceEmbeddings
#HuggingfaceEmbedding 함수로 Open source 임베딩 모델 로드
model_name = "jhgan/ko-sroberta-multitask"
ko_embedding= HuggingFaceEmbeddings(
model_name=model_name
)
examples = ko_embedding.embed_documents(
[
"안녕하세요",
"제 이름은 홍두깨입니다.",
"이름이 무엇인가요?",
"랭체인은 유용합니다.",
]
)
embedded_query_q = ko_embedding.embed_query("이 대화에서 언급된 이름은 무엇입니까?")
embedded_query_a = ko_embedding.embed_query("이 대화에서 언급된 이름은 홍길동입니다.")
print(cos_sim(embedded_query_q, embedded_query_a))
print(cos_sim(embedded_query_q, examples[1]))
print(cos_sim(embedded_query_q, examples[3]))<결과>

4.2.2. 한글 임베딩 지원x 모델(알리바바)
from langchain_community.embeddings import HuggingFaceEmbeddings
model_name = "BAAI/bge-small-en"
bge_embedding= HuggingFaceEmbeddings(
model_name=model_name
)
examples = bge_embedding.embed_documents(
[
"안녕하세요",
"제 이름은 홍두깨입니다.",
"이름이 무엇인가요?",
"랭체인은 유용합니다.",
]
)
embedded_query_q = bge_embedding.embed_query("이 대화에서 언급된 이름은 무엇입니까?")
embedded_query_a = bge_embedding.embed_query("이 대화에서 언급된 이름은 홍길동입니다.")
print(cos_sim(embedded_query_q, embedded_query_a))
print(cos_sim(embedded_query_q, examples[1]))
print(cos_sim(embedded_query_q, examples[3]))
<결과>

전혀 다른 문장임에도 불구하고, 매우 높은 유사도가 나온 것을 확인할 수 있다.