카테고리 없음
4. RAG를 위한 LangChain의 핵심 구성 요소 및 실습[Document Loader]
조찬국
2024. 10. 31. 23:58
728x90
1. Document Loader의 대한 개념
: 주어진 무서를 Rag에서 활용하기 용이한 형태(Document 객체)로 변환하는 역할을 하는게 LangChain의 Document Loader라고 할 수 있다.
Document 객체는 문서의 내용을 담은 Page_content와 메타데이터로 이뤄진 Dictionary이다.

1.1. Page_content
Pdf 데이터에 들어있는 텍스트들이 전부 여기에 들어간다.
1.2. metadata
PDF 파일에 대한 정보이다. 예를들어 쪽별로 분할했을시 이러한 정보에 관한 내용이 들어간다.

2. 실습
2.1. PyPDF Loader
쪽별로 Page_content확인

쪽별로 메타 데이터 확인

전체 page에 대한 정보

2.2 OCR 기능 활용하여 이미지-텍스트 혼합 페이지 내 텍스트 추출하기
<파일의 6페이지 내용>

#OCR기능 위해 설치
!pip install rapidocr-onnxruntime
#PyPDFLoader 불러오기
from langchain_community.document_loaders import PyPDFLoader
# PDF파일 불러올 객체 PyPDFLoader 선언(extract_images 매개변수로 OCR 수행)
loader = PyPDFLoader(r"/content/drive/MyDrive/마소캠퍼스/[이슈리포트 2022-2호] 혁신성장 정책금융 동향.pdf", extract_images=True)
# PDF파일 로드 및 페이지별로 자르기
pages = loader.load_and_split()
print(pages[5].page_content)
OCR은 이미지내의 텍스트를 읽으므로 딥러닝 모델에서 갖고올 때 실행시간이 굉장히 오래 걸린다.
결과

2.3 OCR 기능 활용하여 페이지 내 테이블 추출하기
<파일의 4페이지>

결과

2.4 Office file Loaders
#docx2txt 설치
!pip install --upgrade --quiet docx2txt
#Docx2txtLoader 불러오기
from langchain_community.document_loaders import Docx2txtLoader
#Docx2txtLoader로 워드 파일 불러오기(경로 설정)
loader = Docx2txtLoader(r"/content/drive/MyDrive/마소캠퍼스/[삼성전자] 사업보고서(일반법인) (2021.03.09).docx")
#페이지로 분할하여 불러오기
data = loader.load_and_split()
data[0]
#첫번째 페이지 출력하기
print(data[12].page_content[:500])
print(data[12].metadata)결과

2.5 CSV 파일 불러오기
from langchain_community.document_loaders.csv_loader import CSVLoader
loader = CSVLoader(file_path=r"/content/drive/MyDrive/마소캠퍼스/mlb_teams_2012.csv")
data = loader.load()
data[0]
결과


2.6 인터넷 정보 로드하기, WebBaseLoader
from langchain_community.document_loaders import WebBaseLoader
#텍스트 추출할 URL 입력
loader = WebBaseLoader("https://www.espn.com/")
#ssl verification 에러 방지를 위한 코드
loader.requests_kwargs = {'verify':False}
data = loader.load()
data"verify: False" 는 ssl인증을 하지 않는다.


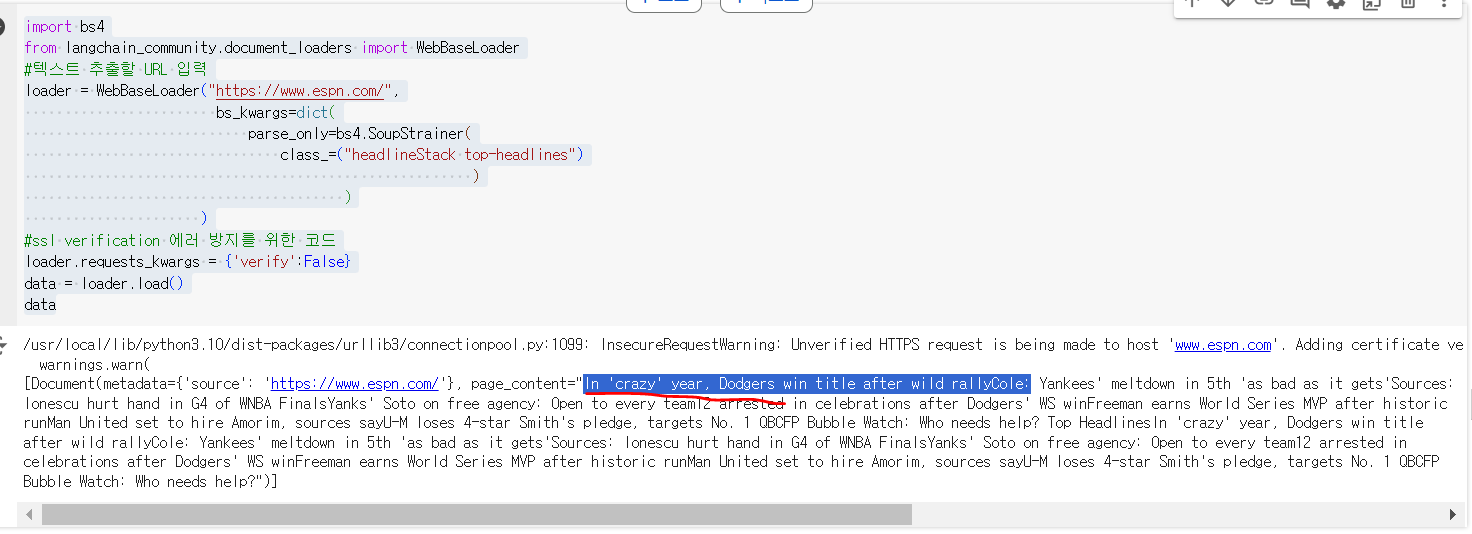
2.6.1 Top Headlines만 가져오기
import bs4
from langchain_community.document_loaders import WebBaseLoader
#텍스트 추출할 URL 입력
loader = WebBaseLoader("https://www.espn.com/",
bs_kwargs=dict(
parse_only=bs4.SoupStrainer(
class_=("headlineStack top-headlines")
)
)
)
#ssl verification 에러 방지를 위한 코드
loader.requests_kwargs = {'verify':False}
data = loader.load()
data
Beautiful Soup Keyword:bs4 => 해당 url의 css 클래스만 지정해서 가져온다.

2.7 특정 경로내의 모든 파일 불러오기, DirectoryLoader
pip install unstructured[pdf]pip install --upgrade nltkOSError: No such file or directory: '/root/nltk_data/tokenizers/punkt/PY3_tab'
이 에러가 발생되면 nltk를 업그레이드 하면 정상적으로 실행된다
from langchain_community.document_loaders import DirectoryLoader
#첫번째 매개변수로 경로 입력, glob에 해당 경로에서 불러들일 파일의 형식 지정
#*는 모든 문자를 표현하는 와일드카드로, .pdf로 끝나는 모든 파일을 의미함
loader = DirectoryLoader(r'/content/drive/MyDrive/마소캠퍼스', glob="*.pdf")
docs = loader.load()
[i.metadata['source'] for i in docs]
glob: 어떤 형식의 파일확장자를 가져올지에 대한 설정
<결과>

2.7 특정 경로내의 모든 파일 불러오기, DirectoryLoader
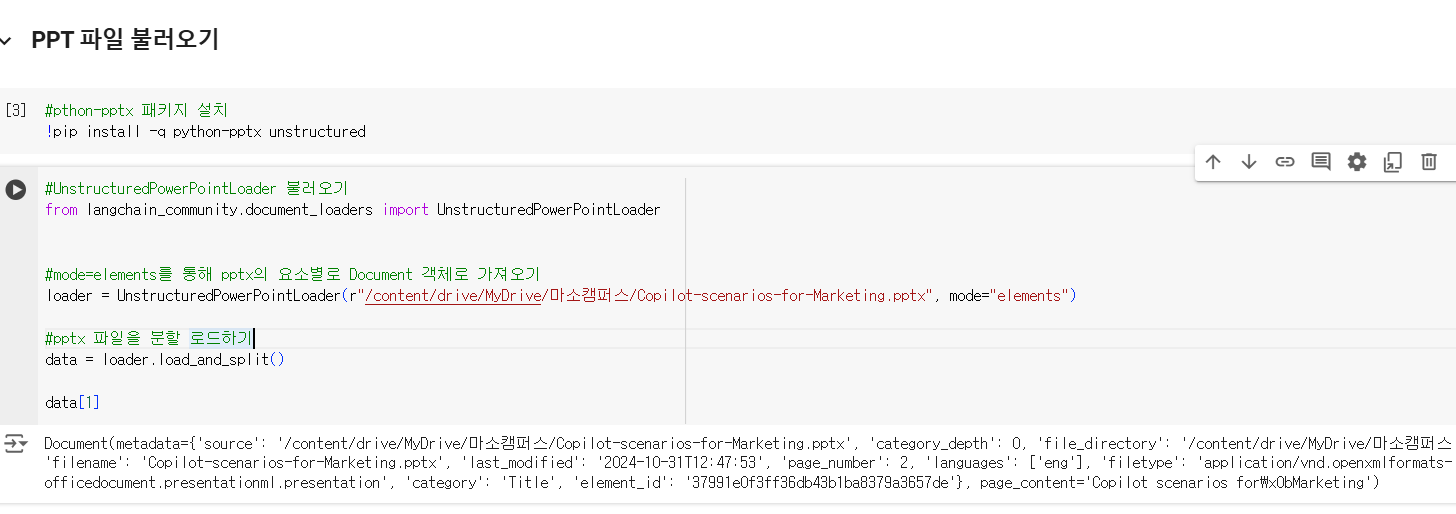
#pthon-pptx 패키지 설치
!pip install -q python-pptx unstructured#UnstructuredPowerPointLoader 불러오기
from langchain_community.document_loaders import UnstructuredPowerPointLoader
#mode=elements를 통해 pptx의 요소별로 Document 객체로 가져오기
loader = UnstructuredPowerPointLoader(r"/content/drive/MyDrive/마소캠퍼스/Copilot-scenarios-for-Marketing.pptx", mode="elements")
#pptx 파일을 분할 로드하기
data = loader.load_and_split()
data[1]
<결과>
728x90