2. RAG를 위한 LangChain의 핵심 구성 요소 및 실습[Models]
1. LangChain API 활용하기
Langchain을 활용하면 다양한 모델 API를 일관된 형식으로 불러올 수 있다.
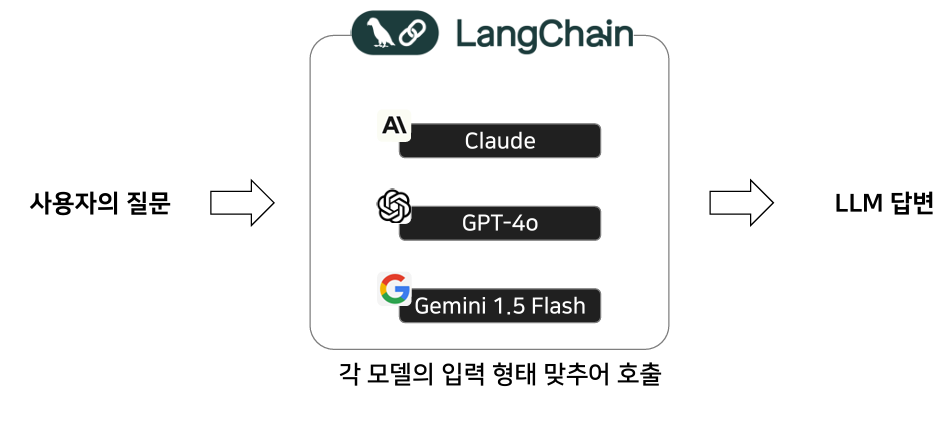
1. 실습은 코렙으로 진행
https://colab.research.google.com/
Google Colab
colab.research.google.com
코렙의 특징
구글에서 무료로 제공하는 딥러닝 환경으로 무료 GPU를 적용할 수 있는 개발 환경
Google Drive와 Jupyter Notebook(.ipynb)을 사용하기에 따로 설치하는 과정이 없고, 클라우드 상에서 동작.
OpenAI와 Anthropic의 모듈을 활용할 수 있도록 라이브러리 설치
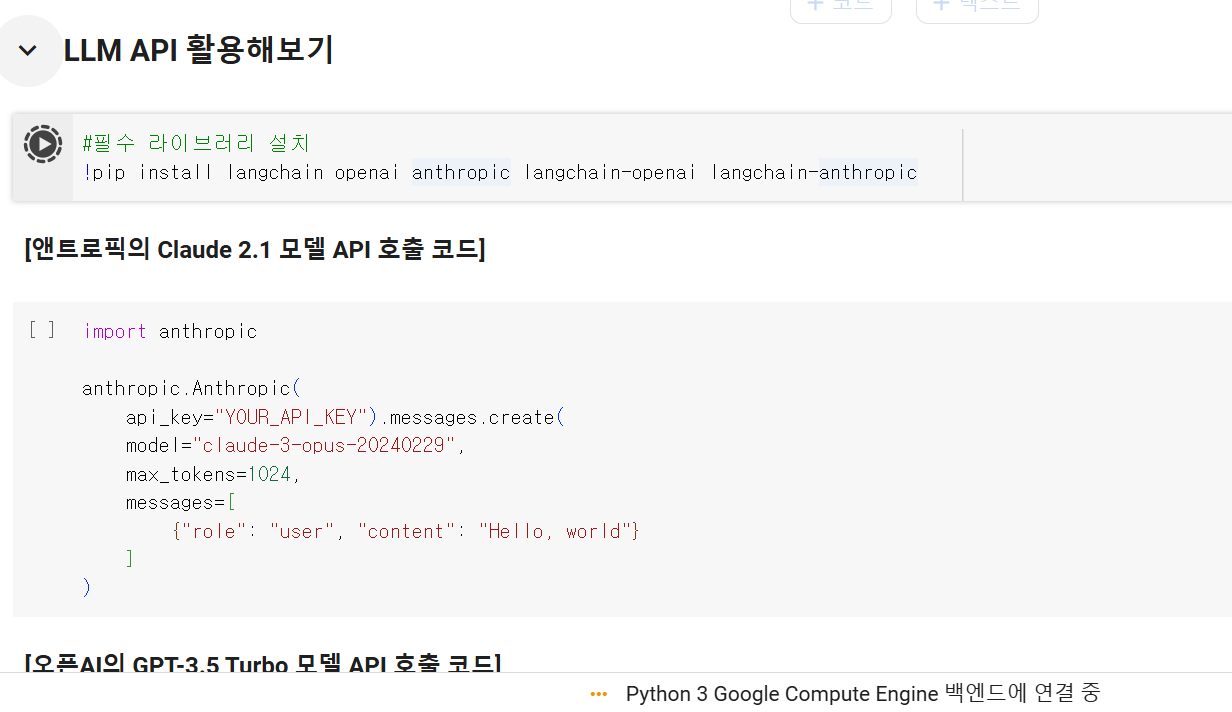
코드 설명: 어떠한 모델을 쓰고, 출력 길이는 1024로 설정되며, 어떤 메시지에 대한 내용을 처리할지 메시지를 보낸다.
2. LangChain과 일반 프롬프트 비교
2.1. 엔트로픽 계정 생성
2.2. 엔트로픽 API 키 생성

2.3. 엔트로픽 Claude 2.1 모델 API 호출
import anthropic
anthropic.Anthropic(
api_key="API 키").messages.create(
model="claude-3-opus-20240229",
max_tokens=1024,
messages=[
{"role": "user", "content": "Hello, world"}
]
)
5달러는 충전해야 호출할 수 있습니다!
2.4. GPT-3.5 Turnbo 모델 API 호출
from openai import OpenAI
client = OpenAI(api_key = "API키")
client.chat.completions.create(
model="gpt-4o-mini",
messages=[
{
"role": "user",
"content": "Who won the world series in 2020?"
}
]
)
5달러는 충전해야 호출할 수 있습니다! 만약 충전전에 호출하면 에러가 발생한다.
이때 충전 후, api 키를 다시 발급받아 복붙하면 사용가능하다.

대답 토큰 수: 43개, 프롬프트 토큰수 17개, 총 토큰수 60개 사용됨
2.5. "랭체인"을 활용한 앤트로픽 Claude 2.1 모델 API 호출 코드
from langchain_anthropic import ChatAnthropic
chat = ChatAnthropic(
model_name ="claude-3-opus-20240229",
anthropic_api_key="API 키"
)
chat.invoke("안녕~ 너를 소개해줄래?")<결과>

Response MeatData: 이 메시지의 아이디와 어떤 모델 등 Langchain사용 이전 호출보다 정제된 내용을 받을 수 있다.
2.6. "랭체인"을 활용한 오픈AI GPT-4o-mini 모델 API 호출 코드
from langchain_openai import ChatOpenAI
chat = ChatOpenAI(
model_name = 'gpt-4o',
openai_api_key="YOUR_API_KEY"
)
chat.invoke("안녕~ 너를 소개해줄래?")<결과>

LangChain을 활용하면 모델이 달라도 코드형태도 같고, 답변 형식도 똑같다. 이는 LangChain의 후처리 모듈에 의해 응답 값이 같아지게 되기 때문이다.
2.7. 프롬프트 이해하기
2.7.1. LangChain에서는 LLM에게 보내는 프롬프트의 형식을 크게 3가지로 구분

2.7.1.1. SystemMessage : LLM에게 역할을 부여하는메시지(조금 더 고품질의 답변 가능)
2.7.1.2. HumanMessage : LLM에게전달하는 사용자의메시지
2.7.1.3. AIMessage : LLM이 출력한 메시지-> LLM에게 메모리를 전달하기 위해 즉, 이전 답변이 다음 답변에도 영향을 줘야하기 때문이다.
2.7.2. LLM의 매개변수 중 하나인 Temperature는 답변의 일관성을 조정한다.

오늘의 날씨가 뒤에 나올 단어가 맑다가 자주 나오게 되던게 출현 확률을 조정해서 고르게도 나오게 할 수 있다.
낮은 온도: 출현 확률이 높은 단어의 학률이 증가되고, 다른 단어들은 낮아진다.
높은 온도: 출현 확률이 비슷해진다.
#API KEY 저장을 위한 os 라이브러리 호출
import os
#OPENAI API키 저장
os.environ["OPENAI_API_KEY"] = "YOUR_API_KEY"
#Temperature=0
chatgpt_temp0_1 = ChatOpenAI(model_name="gpt-3.5-turbo-0125", temperature = 0)
chatgpt_temp0_2 = ChatOpenAI(model_name="gpt-3.5-turbo-0125", temperature = 0)
#Temperature=1
chatgpt_temp1_1 = ChatOpenAI(model_name="gpt-3.5-turbo-0125", temperature = 1)
chatgpt_temp1_2 = ChatOpenAI(model_name="gpt-3.5-turbo-0125", temperature = 1)
model_list = [chatgpt_temp0_1, chatgpt_temp0_2, chatgpt_temp1_1, chatgpt_temp1_2]
for i in model_list:
answer = i.invoke("왜 파이썬이 가장 인기있는 프로그래밍 언어인지 한 문장으로 설명해줘", max_tokens = 128)
print("-"*100)
print(">>>",answer.content)

온도가 낮을수록 일관성이 있다 -> 비슷한 단어만 나온다.
온도가 높을수록 일관성이 없다 -> 비슷하지 않은 단어가 주로 나온다.
temperature는 0~1 사이로 설정하면 됩니다!(소수점 가능)
2.7.3. Langchain을 활용하면 LLM의 답변을 ChatGPT처럼 스트리밍할 수 있다.

flush를 켜야 타이핑 치듯이 스트리밍할 수 있다.
2.7.4. LLM 답변 캐싱하기

[실습]
1. 첫번째 질문 실행 전에 실행 시간: 2.15 ms
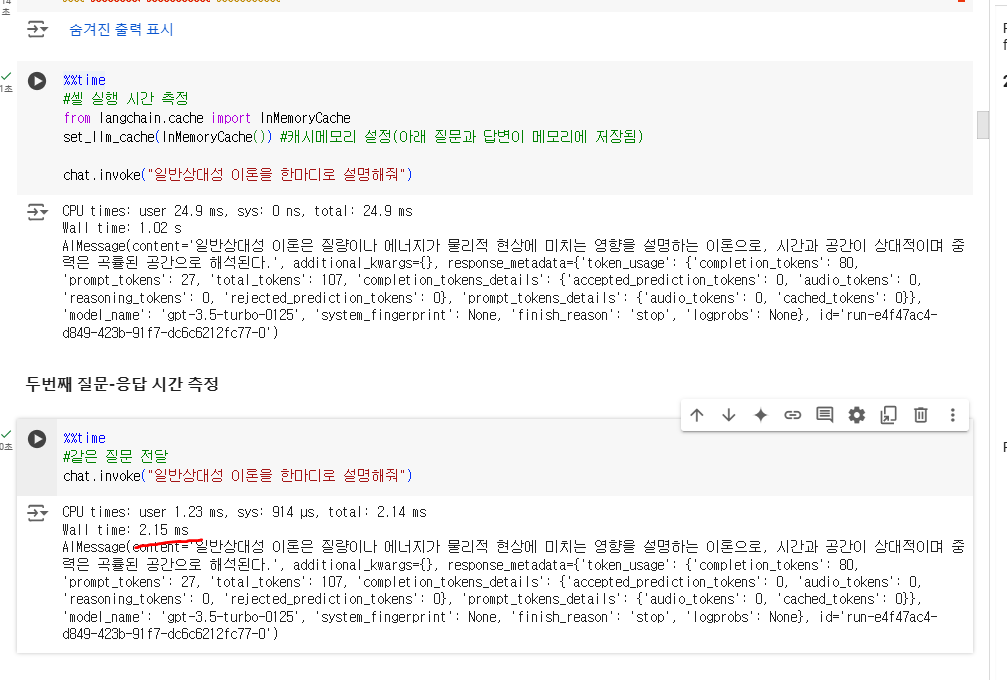
2. 첫번째 질문 실행 후에 실행 시간: 1.77 ms

질문을 할때마다 캐시에 저장해두면 이를 캐시에서 같은 질문에 대한 답을 함으로써 속도가 향상된다.