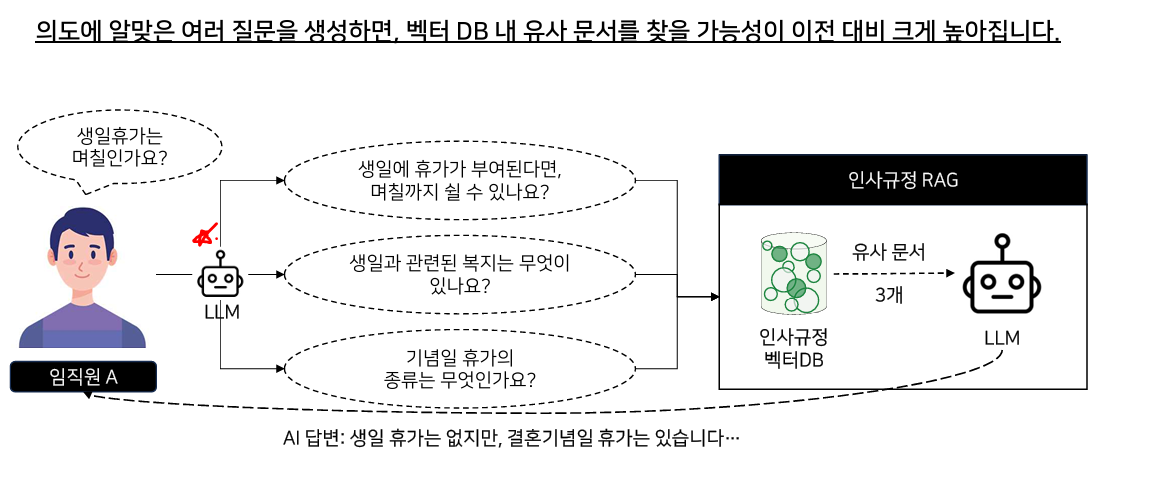
1. 다중 쿼리 생성(Multi-query Retriever) 기법
1.1. 기존 RAG의 문제점
기존의 RAG는 사용자의 질문이 모호할 경우, 벡터 DB 내 문장들과 매칭되지 않는 경우가 있다.

1.2. MultiQueryRetriever 원리
MultiQueryRetriever는 사용자 질문의 의도를 LLM이 이해하여 이를 여러 질문으로 재생성합니다.
1.3.
1.3. Chroma DB에 문서 벡터 저장
from langchain.document_loaders import PyPDFLoader
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain_openai import OpenAIEmbeddings
from langchain_community.vectorstores import Chroma
#헌법 PDF 파일 로드
loader = PyPDFLoader(r"/content/drive/MyDrive/마소캠퍼스/대한민국 헌법.pdf")
pages = loader.load_and_split()
#PDF 파일을 500자 청크로 분할
text_splitter = RecursiveCharacterTextSplitter(chunk_size=500, chunk_overlap=0)
docs = text_splitter.split_documents(pages)
#ChromaDB에 청크들을 벡터 임베딩으로 저장(OpenAI 임베딩 모델 활용)
db = Chroma.from_documents(docs, OpenAIEmbeddings(model = 'text-embedding-3-small'))1.4. 질문을 여러 버전으로 재해석하여 Retriever에 활용
#```Chroma DB에 대한민국 헌법 PDF 임베딩 변환 및 저장하는 과정은 위 셀에 있습니다```
from langchain.retrievers.multi_query import MultiQueryRetriever
from langchain_openai import ChatOpenAI
#질문 문장 question으로 저장
question = "국회의원의 의무는 무엇이 있나요?"
#여러 버전의 질문으로 변환하는 역할을 맡을 LLM 선언
llm = ChatOpenAI(model_name="gpt-3.5-turbo-0125",
temperature = 0)
#MultiQueryRetriever에 벡터DB 기반 Retriever와 LLM 선언
retriever_from_llm = MultiQueryRetriever.from_llm(
retriever=db.as_retriever(), llm=llm
)
# 여러 버전의 문장 생성 결과를 확인하기 위한 로깅 과정
import logging
logging.basicConfig()
logging.getLogger("langchain.retrievers.multi_query").setLevel(logging.INFO)
#여러 버전 질문 생성 결과와 유사 청크 검색 개수 출력
unique_docs = retriever_from_llm.invoke(input=question)
len(unique_docs)<결과>

질문의 의도를 잘 파악해서 질문을 잘 추출했다.
2. 컨텍스트 재정렬, Long-Context Reorder
2.1. Needle in a Haystack
LLM의 컨텍스트 사이즈가 늘어나며, 긴 입력이 가능해졌지만 중간 문서는 잘 찾지 못하는 문제가 있다.

문장의 길이가 길수록 정확도가 낮아진다. (100%는 잘 대답해준다.)
2.2. 문서의 앞,뒤에 따라서도 정확도가 달라진다.

2.3. 실습
2.3.1. 단순 추출
from langchain.prompts import PromptTemplate
from langchain_community.document_transformers import (
LongContextReorder,
)
from langchain_community.vectorstores import FAISS
from langchain_openai import OpenAI
texts = [
"바스켓볼은 훌륭한 스포츠입니다.",
"플라이 미 투 더 문은 제가 가장 좋아하는 노래 중 하나입니다.",
"셀틱스는 제가 가장 좋아하는 팀입니다.",
"이것은 보스턴 셀틱스에 관한 문서입니다."
"저는 단순히 영화 보러 가는 것을 좋아합니다",
"보스턴 셀틱스가 20점차로 이겼어요",
"이것은 그냥 임의의 텍스트입니다.",
"엘든 링은 지난 15 년 동안 최고의 게임 중 하나입니다.",
"L. 코넷은 최고의 셀틱스 선수 중 한 명입니다.",
"래리 버드는 상징적인 NBA 선수였습니다.",
]
# Chroma Retriever 선언(10개의 유사 문서 출력)
retriever = FAISS.from_texts(texts, OpenAIEmbeddings(model = 'text-embedding-3-small')).as_retriever(
search_kwargs={"k": 10}
)
query = "셀틱에 대해 설명해줘"
# 유사도 기준으로 검색 결과 출력
docs = retriever.invoke(query)
for i in docs:
print(i.page_content)<결과>

2.3.2. Long-Context Reorder 활용하여 유사 문서 출력
#LongContextReorder 선언
reordering = LongContextReorder()
#검색된 유사문서 중 관련도가 높은 문서를 맨앞과 맨뒤에 재정배치
reordered_docs = reordering.transform_documents(docs)
for i in reordered_docs:
print(i.page_content)<결과 >

Long-Context Reorder 를 문장의 앞,뒤에 "셀틱스"와 관련된 문장들을 재배치하여 LLM에 질문시에 정확도를 높일 수 있다.
3. 맥락 압축(Context Compression) 기법
3.1. 맥락압축의 필요성
RAG가제대로작동하려면, 알맞은 유사 문서만 검색되어야만 하지만 그렇지 않은 경우가 있습니다.
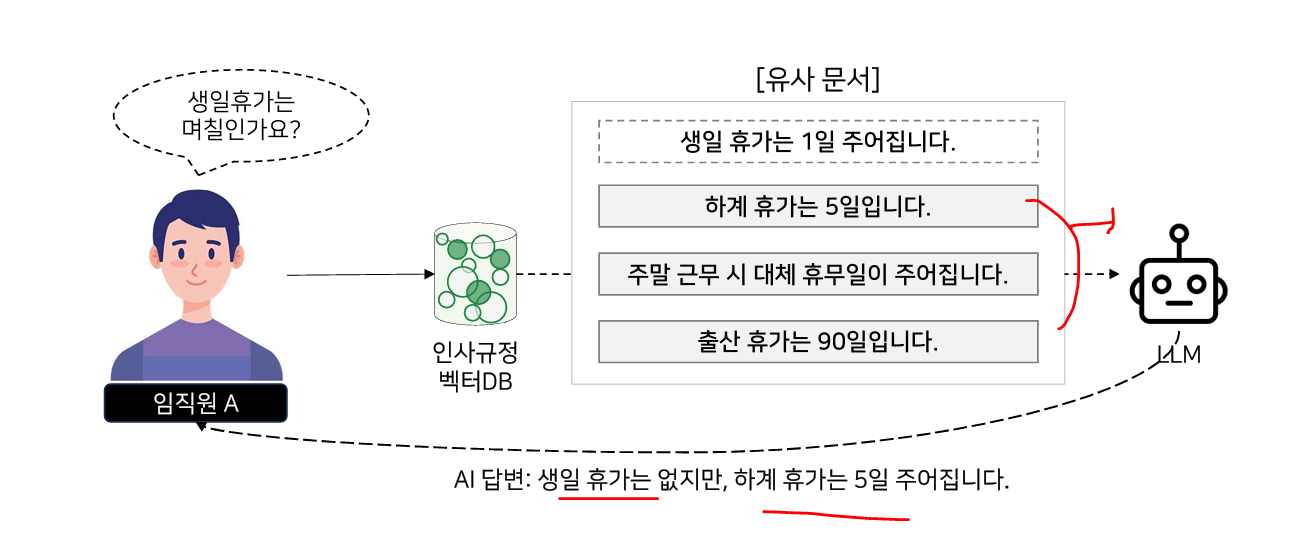
3.2. 맥락압축의 개념

유사하지 않은 문장들은 제거하여 LLM에게 전달하여, 사용자 질문에 의도한 답변을 얻어낸다.
3.3. 실습
3.3.1. 가독성 좋게 하는 메서드
# Helper function for printing docs
def pretty_print_docs(docs):
print(
f"\n{'-' * 100}\n".join(
[f"Document {i+1}:\n\n" + d.page_content for i, d in enumerate(docs)]
)
)
from langchain_community.vectorstores import FAISS
from langchain_openai import OpenAIEmbeddings
from langchain_text_splitters import RecursiveJsonSplitter
loader = PyPDFLoader(r"/content/drive/MyDrive/마소캠퍼스/대한민국 헌법.pdf")
pages = loader.load_and_split()
text_splitter = RecursiveCharacterTextSplitter(chunk_size=500, chunk_overlap=0)
docs = text_splitter.split_documents(pages)
db = FAISS.from_documents(docs, OpenAIEmbeddings(model = 'text-embedding-3-small'))
retriever =db.as_retriever()
docs = retriever.invoke("대통령의 임기는?")
pretty_print_docs(docs)<결과>

A는 유사한 답변이지만, B는 유사하지 않은 답변이다.
3.3.2. LLMChainExtractor
from langchain.retrievers import ContextualCompressionRetriever
from langchain.retrievers.document_compressors import LLMChainExtractor
from langchain_openai import OpenAI
llm = ChatOpenAI(model ='gpt-4o-mini', temperature=0)
compressor = LLMChainExtractor.from_llm(llm)
compression_retriever = ContextualCompressionRetriever(
base_compressor=compressor, base_retriever=retriever
)
compressed_docs = compression_retriever.invoke(
"대통령의 임기는?"
)
pretty_print_docs(compressed_docs)<결과>

LLM이 문장들에서 유사한 문장들만 남기고 삭제한다.
3.3.3. LLMChainFilter

LLMChainFilter는 LLMChainExtractor와 달리 아예 "문서"를 삭제한다.
3.3.4. pipeline_compressor 로 두개의 맥락압축기를 연동해서 사용 ( LLMChainExtractor, EmbeddingsFilter)
즉, 사용자의 질문과 유사한 문장만 남긴다.
from langchain.retrievers.document_compressors import DocumentCompressorPipeline
from langchain_community.document_transformers import EmbeddingsRedundantFilter
from langchain.retrievers.document_compressors import EmbeddingsFilter
from langchain_text_splitters import CharacterTextSplitter
llm = ChatOpenAI(model ='gpt-4o-mini', temperature=0)
splitter = CharacterTextSplitter(chunk_size=300, chunk_overlap=0, separator=". ")
compressor = LLMChainExtractor.from_llm(llm)
# 사용자의 질문에서 유사도 0.4 이하는 임베딩에서 필터
relevant_filter = EmbeddingsFilter(embeddings=OpenAIEmbeddings(model = 'text-embedding-3-small'), similarity_threshold=0.4)
pipeline_compressor = DocumentCompressorPipeline(
transformers=[splitter, relevant_filter, compressor]
)
compression_retriever = ContextualCompressionRetriever(
base_compressor=pipeline_compressor, base_retriever=retriever
)
compressed_docs = compression_retriever.invoke(
"대통령의 임기는?"
)
pretty_print_docs(compressed_docs)
<결과>

임기와 관련된 문서만 남기고, 문장만 남게 되었다.
4. 가상 문서로 유사 문서 탐색, HyDE(Hypothetical Document Embedding)
4.1. 기존RAG의문제와HyDE

질문은 의문문이고, 벡터DB에 저장된건 평문이다. (생일 휴가는 00일이다.) 이로 인해 사용자의 질문과 유사도가 높게 나오지 않는다. 따라서 사용자의 질문에 따라 가상의 답변을 작성하여 이 문장들과 벡터 DB의 문장들을 비교함으로써 LLM의 답변을 잘 갖고 오도록한다.
4.2. 실습
4.2.1 system에 가상 문서를 만들어 달라는 Prompt를 짜기
from langchain_core.output_parsers import StrOutputParser
from langchain_core.prompts import ChatPromptTemplate
from langchain_openai import ChatOpenAI
system = """
당신은 LangChain, LangGraph, LangServe, LangSmith라는 LLM 기반 애플리케이션을 구축하기 위한 일련의 소프트웨어에 대한 전문가입니다.
LangChain은 LLM 애플리케이션을 구축하기 위해 쉽게 구성할 수 있는 대규모 통합 세트를 제공하는 Python 프레임워크입니다.
LangGraph는 상태 저장, 멀티 액터 LLM 애플리케이션을 쉽게 구축할 수 있는 LangChain 위에 구축된 Python 패키지입니다.
LangServe는 REST API로 LangChain 애플리케이션을 쉽게 배포할 수 있는 LangChain 위에 구축된 Python 패키지입니다.
LangSmith는 LLM 애플리케이션 추적 및 테스트를 쉽게 할 수 있는 플랫폼입니다.
사용자 질문에 최선을 다해 답변하세요. 사용자 질문에 대한 튜토리얼을 작성하는 것처럼 답변하세요.
"""
prompt = ChatPromptTemplate.from_messages(
[
("system", system),
("human", "{question}"),
]
)
llm = ChatOpenAI(model="gpt-4o-mini", temperature=0)
qa_no_context = prompt | llm | StrOutputParser()
answer = qa_no_context.invoke(
{
"question": "Chain을 구축할 때 멀티모달 모델을 활용하는 방법과 Chain을 REST API로 전환하는 방법"
}
)
print(answer)

프롬프트에 기반하여 답변을
4.3. hypothetical_document에 qa_no_context라는 키 값으로 설정하기
from langchain_core.runnables import RunnablePassthrough
hyde_chain = RunnablePassthrough.assign(hypothetical_document=qa_no_context)
hyde_chain.invoke(
{
"question": "Chain을 구축할 때 멀티모달 모델을 활용하는 방법과 Chain을 REST API로 전환하는 방법"
}<결과>

사용자의 질문에 가상의 문서를 생성함을 확인할 수 있다. 이를 통해 벡터 db와 연동해서 효율을 높인다.
'Chatbot 프로젝트 > LangChain' 카테고리의 다른 글
| 10. Runnable 인터페이스와 체이닝 (0) | 2024.11.25 |
|---|---|
| 9. LCEL 소개 및 기본 구조 (0) | 2024.11.24 |
| 8. RAG를 위한 LangChain의 핵심 구성 요소 및 실습[Retrievers] (0) | 2024.11.24 |
| 7. RAG를 위한 LangChain의 핵심 구성 요소 및 실습[Vector Stores] (0) | 2024.11.24 |
| 6. RAG를 위한 LangChain의 핵심 구성 요소 및 실습[Embeddings] (0) | 2024.11.01 |